Merge DataFrames in Pandas
In my last post, I wrote about some basic functions of Pandas and DataFrames. Today, I show you how to read DataFrames from Excel. The Scenario is (again) about configuration generation, but this time I like to focus on the data gathering part. The example code is also a jupyter notebook that is part of my python scripting repository on GitHub.
The Scenario
I already wrote about configuration generation and the various ways how to create an efficient template that also contains some logic. The focus of this post should be the collection of the parameters that we need to create configurations. In many cases you’ll create (or receive) an Excel workbook that contains the information required for the configuration. I saw many workbooks during my day job for this purpose, from simple (single sheet with some parameters) to complex (up to a 5 MB workbook with a ton of sheets and many, many parameters…).
In my scenario for this post, we use a simple workbook with four sheets (it’s also part of the repository, therefore I won’t go down to the parameter level):
- device – that contains basic information about all hosts
- ip_network – some basic layer 2/3 information associated to the devices
- port_role – some common configuration template for the interfaces on the device
- interface – the physical interfaces available on the devices
These sheets are “linked” together based on a common column name. In databases you would work with relations based on primary and foreign keys. I know that many people use a similar construct within Excel sheets (if this is useful or not shouldn’t be part of the discussion in this post 😉). The relationships between the sheets in out example workbook are outlined in the following graphic.
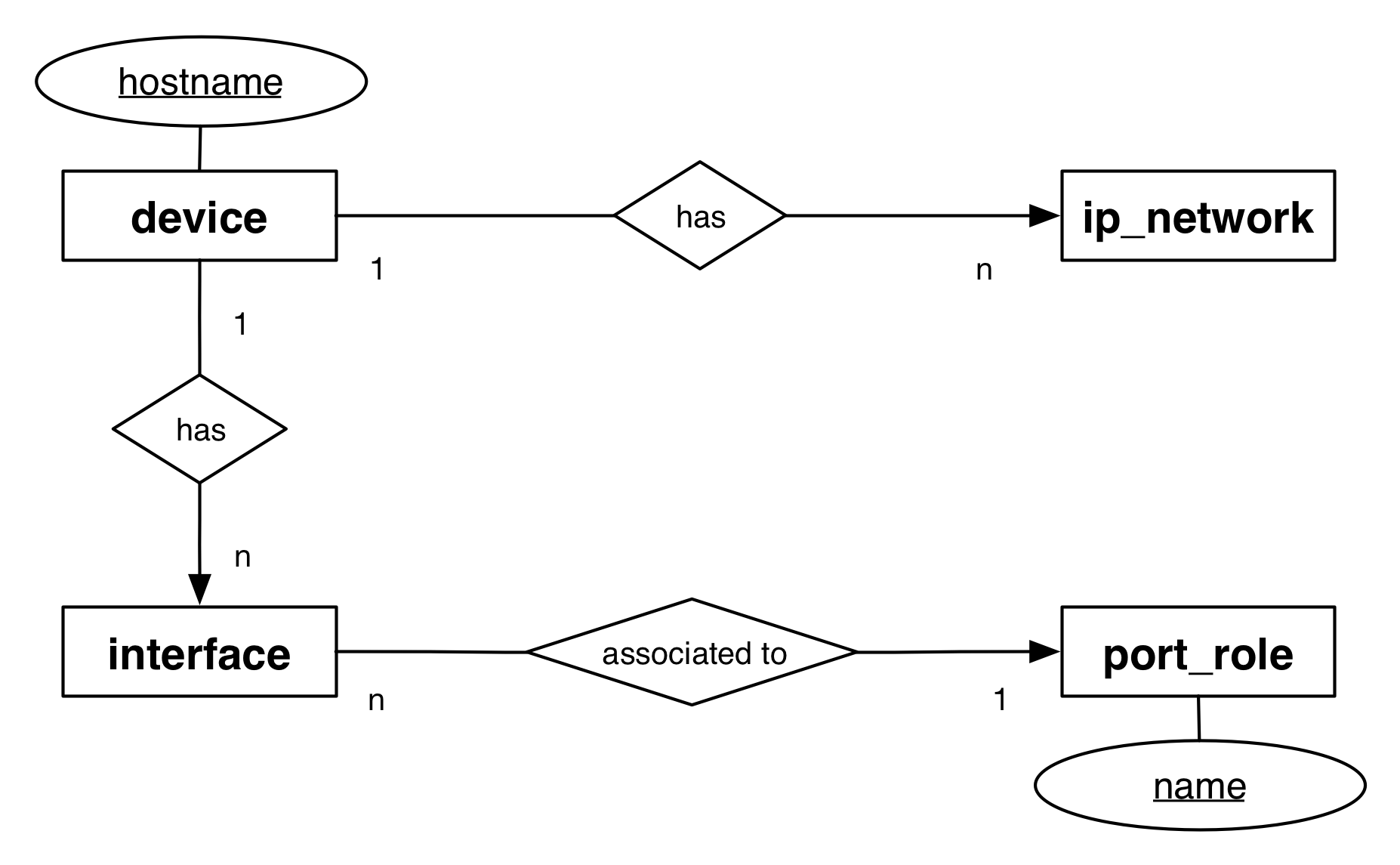
Within the jupyter notebook, we create a parameter model for a device based on the interfaces and port roles sheet. The other sheets are not used within the example code for this post. I think you can practice the work with Excel and pandas using this workbook later on (e.g. merge the data from the ip_network with the device).
Okay, now lets have a look how we can work with pandas DataFrames and Excel.
Read DataFrames from Excel
I already wrote about some capabilities how pandas can read DataFrames from websites in my last post at Pandas DataFrames 101. The way to create a new DataFrame based on an Excel workbook is very similar:

This will create a DataFrame from the sheet interfaces. It will throw an exception if the sheetname is not found in the Excel file. That’s it. By default, Pandas will figure out what are the header values and the rows of your table. From my experience, this works very well. You can also modify this behaviour by specifying the header parameter. Additional information about this function is available in the pandas documentation.
Merge DataFrames in Python
In our example, we like to create one DataFrame that contains all parameters that are required to configure an interface. For this reason, we need to merge the table interface with the table port_role based on the name of the port_role. This task can be accomplished by using the function called merge that is provided by pandas. It requires two DataFrames and merges the content based on common columns values. The result is a new DataFrame that contains the merged data.
The following statement merges the interface_df and the port_role_df. Because the names of the columns that should be used when merging the data are different in both DataFrames, we need to specify the left_on and right_on parameter. This parameter identifies the column names that should be used for the merge operation.
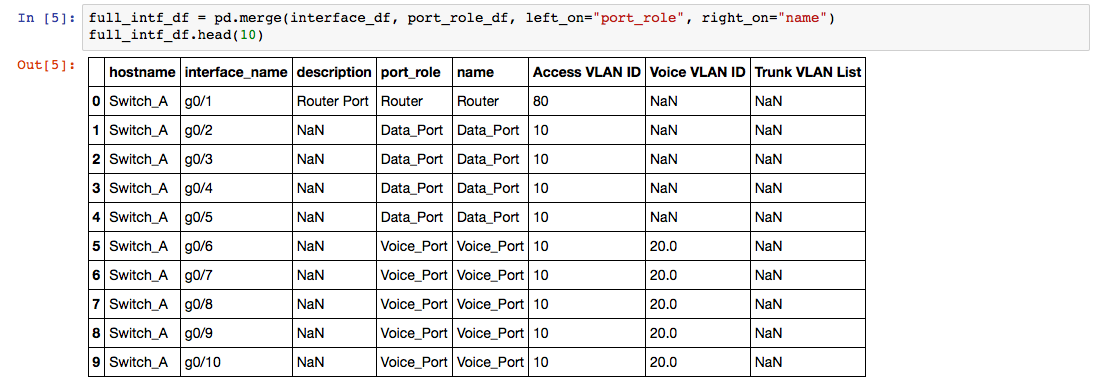
We now have a new DataFrame that contains all information required to configure the interfaces of Switch_A. As you can see, pandas copies the values from the right table, which is great because we only need to define a port role once and it’s copied multiple times during the merge operation. This makes life easier, when creating the parameter set or the configuration.
Further steps
The example code contains more than just these steps, including some data cleaning and the export as a python dictionary. I think it’s easier to view the steps directly in the jupyter notebook on GitHub.
Okay, thats it for today. Don’t get me wrong, I don’t think that large and complex parameter sets should be collected within Excel sheets. At some point, I always tend to use a database rather than Excel sheets, but Excel is in many cases the number one data source. Now it’s up to you. Go to GitHub, clone the repository and try it out. You can also extend the data or combine it with a configuration generator based on my post about jinja2 and python.
Thats it for today, thank you for reading.
Links within this post / further reading
- 10 minutes to pandas (quick introduction - official pandas documentation)
- read_excel pandas documentation